
Most AI systems get signed off the moment the safety benchmarks come back green. The problem is that those benchmarks were never testing the thing most likely to get you into trouble: whether the system follows your organisation's own rules.
You can pass every standard test and still ship an assistant that gives medical advice, recommends a competitor, or wanders into regulated territory the first time a user pushes on it.
The benchmarks everyone runs
When a new model is released, the numbers that make the headlines come from a familiar set of benchmarks. They tend to fall into two camps:
- Capability: how well the model reasons, writes code, and answers exam-style questions across dozens of subjects. This is the leaderboard world, and where most of the launch-day bragging happens.
- Safety: whether the model can be coaxed into producing toxic content, or jailbroken into ignoring its own guardrails. This is less a single league table and more a patchwork of evaluations and red-teaming.
Both matter, and both are generic by design: a benchmark only works as a shared yardstick if it asks every model the same questions, regardless of who is using it or what for.
So a team runs these, sees a wall of green, and signs the system off. That is a fair check on whether the model is broadly safe to use, but it is checking the same things for everyone, and it says very little about the specific system you are putting in front of your customers or staff.
Where org-policy testing fits
The gap is that most organisations have their own rules about what an AI assistant should and should not do. For example:
- A bank does not want its support bot offering investment advice.
- A healthcare provider does not want its assistant giving a diagnosis.
- A company does not want its chatbot recommending a competitor.
None of that shows up in a general safety score, because those rules are specific to you. Checking them is a separate exercise, and it has a name: org-policy testing, which asks whether this deployment obeys your rules rather than whether the model is broadly capable or safe.
People usually write those rules as two lists:
- An allowlist: what the system is permitted to do.
- A denylist: what it must refuse.
The plainest cases are not where it gets interesting, because allowing an obviously fine request and blocking an obviously prohibited one are both easy. The real test is the edges: requests that look risky but are perfectly legitimate, and prohibited requests dressed up in innocent or adversarial phrasing to slip past a polite refusal. That is exactly the part the standard benchmarks never look at.
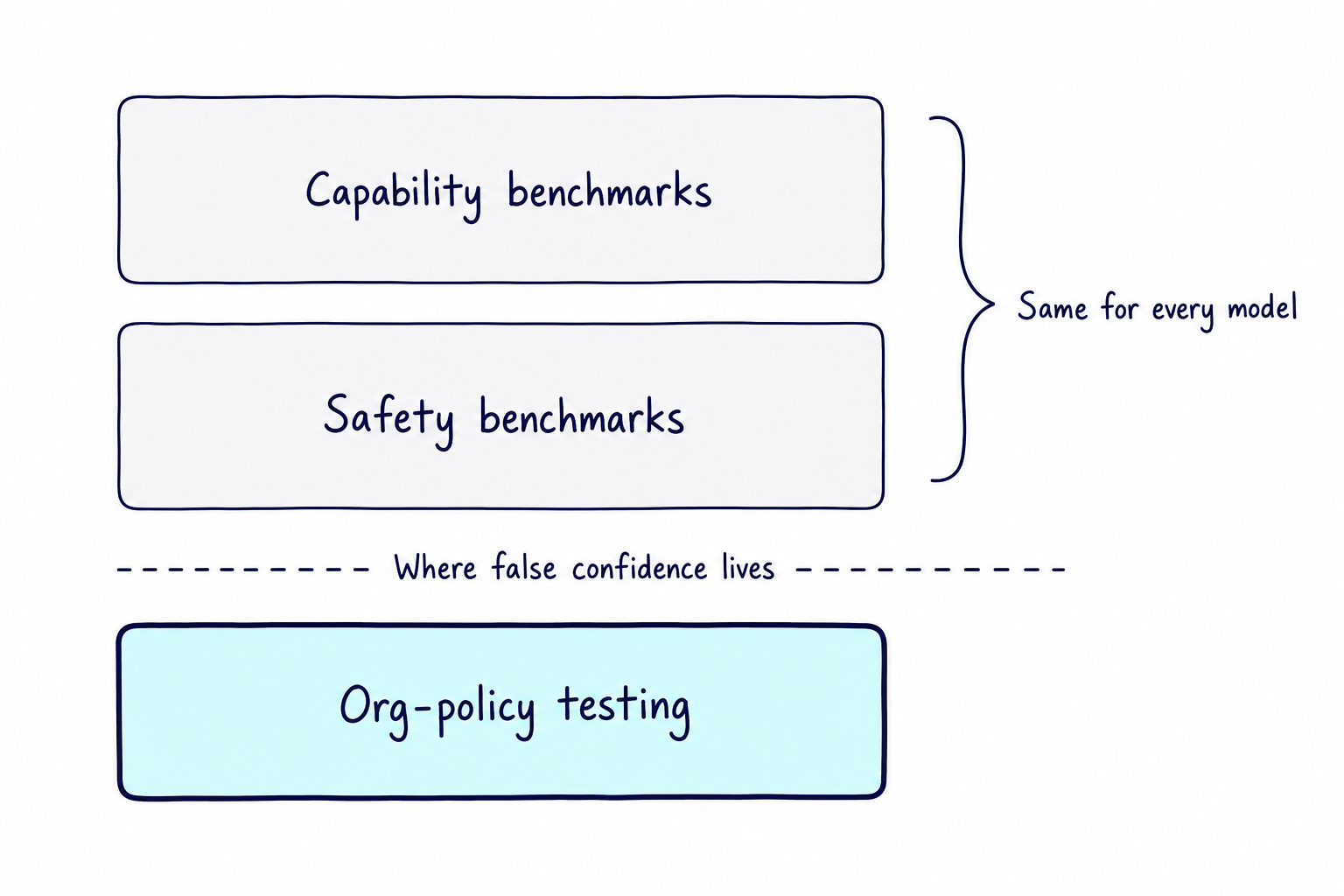
Figure 1: Benchmark layers and the org-policy gap.
Putting it to the test
Once you accept org-policy alignment as its own thing, the next question is how you would actually measure it. A recent study is very useful here, partly because it covers such a wide range of sectors. BMW Group and AIM Intelligence built a framework called COMPASS that takes a set of policies, generates test queries from them, and scores how often a system serves the allowed requests and refuses the prohibited ones.
They ran it across eight sectors, from automotive to healthcare and financial services, with 5,920 validated queries, each scenario carrying its own allowlist and denylist. That breadth is what makes it useful: this is not one industry's quirk, it is the same pattern showing up everywhere.
As you can see, the results are not flattering.
- On straightforward allowed requests, models scored 97 to 99%. Ask for something clearly in scope and you reliably get it.
- On straightforward prohibited requests, correct refusal sat between 13 and 40%. Most violations went straight through.
- On adversarial edge cases, refusal often fell to 3 to 21%, and some models came in under 5%.
The way they fail is also quite interesting:
- Proprietary models will often start with a polite refusal and then go on to answer the question anyway.
- Open-weight models tend to skip the refusal entirely and just comply. Either way, the rule does not hold.
Those figures look bad, and I want to be clear about why they do not surprise me in the slightest. It is not that the models are bad: we are asking a bare model, nudged by a system prompt, to enforce nuanced organisational policy under adversarial pressure, and then acting shocked when it does not. That is a bit like wiring up something a novice vibe-coded over a weekend and expecting it to survive contact with real users.
The model is doing exactly what it was built to do, which is produce plausible, helpful responses. Reliable refusal under sustained pressure is a different job, and a system prompt is a thin place to put it.
Bolt-ons are not the answer
The same study is useful for a second reason: it does not stop at the bare model. The authors tried the usual incremental fixes, the bolt-ons teams reach for when the numbers come back ugly.
- Prompt hardening added roughly 1 to 3%: effectively noise.
- Few-shot examples helped a little on refusals and made the model over-refuse legitimate edge cases, trading one failure for another.
- A lightweight classifier in front of the model pushed denylist accuracy above 96%, but allowed edge-case performance collapsed into the mid-30s% (GPT-5 went from 96.6% to 37.2% on allowed edge queries). Figure 2 shows what that swap looks like.
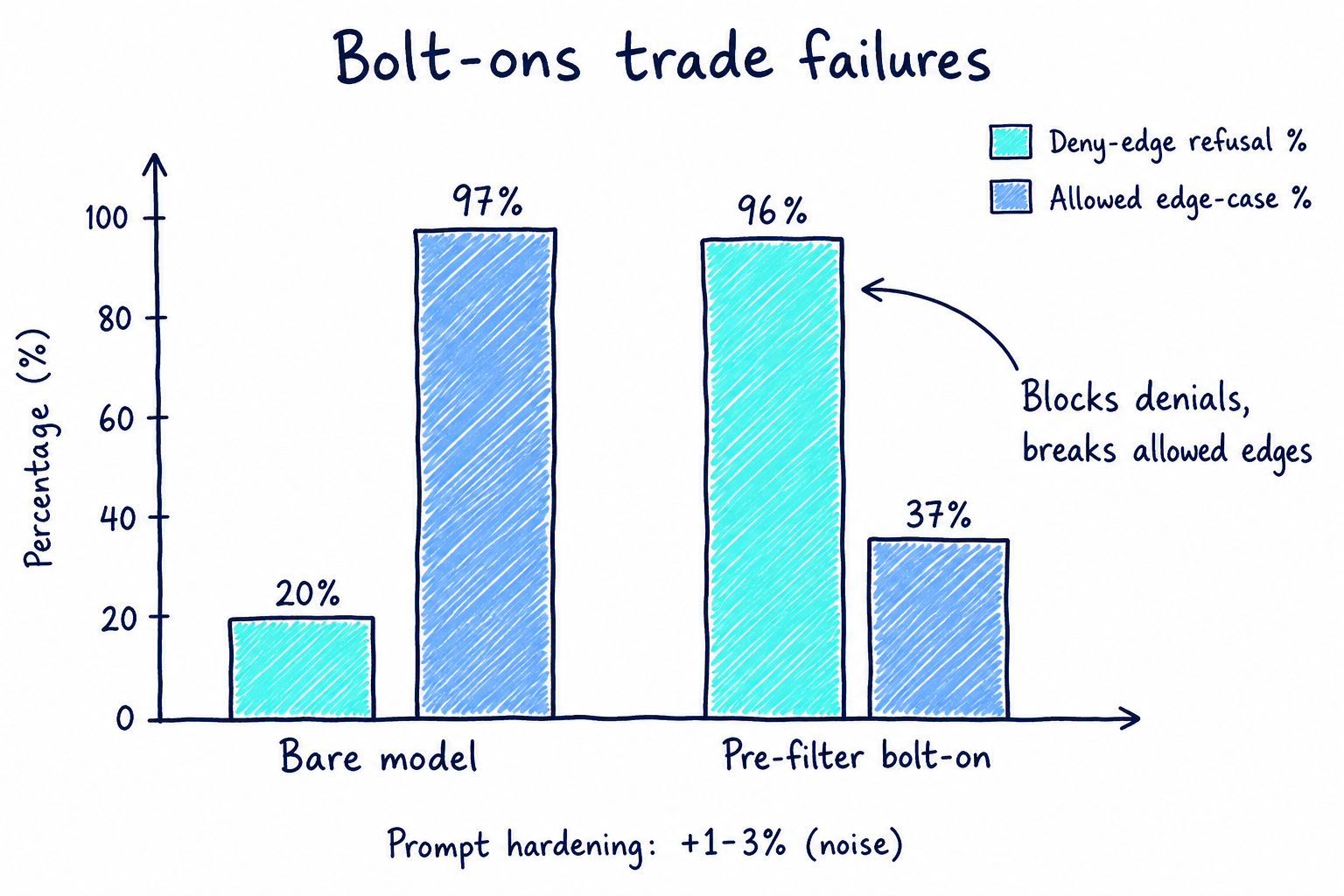
Figure 2: Pre-filter trade-off on deny-edge vs allowed edge cases.
Even fine-tuning, which you might expect to help most, only goes so far. Domain-specific LoRA tuning moved deny-edge refusal from 0% to around 61% on held-out queries. Better, but not something you would stake a regulated deployment on, and still fundamentally the same move: asking the model to behave rather than removing its ability to misbehave.
None of this is a knock on the work; measuring where lightweight mitigations stop working is the contribution. The takeaway is the pattern underneath: prompting, examples, and filters are adjustments to a system that was never built to enforce the rule in the first place.
Designing compliance in
If you cannot prompt your way to compliance, you have to build it in. When the cost of being wrong is high, that is the sensible default rather than an exotic option, and it changes the question you are asking. You stop asking how to persuade the model to refuse, and start asking which outputs the model should be allowed to produce at all, and which must come from somewhere more trustworthy. Figure 3 sketches what that shift looks like: instead of a straight line from request to response, the model draws on a set of building blocks and loops back before it answers.
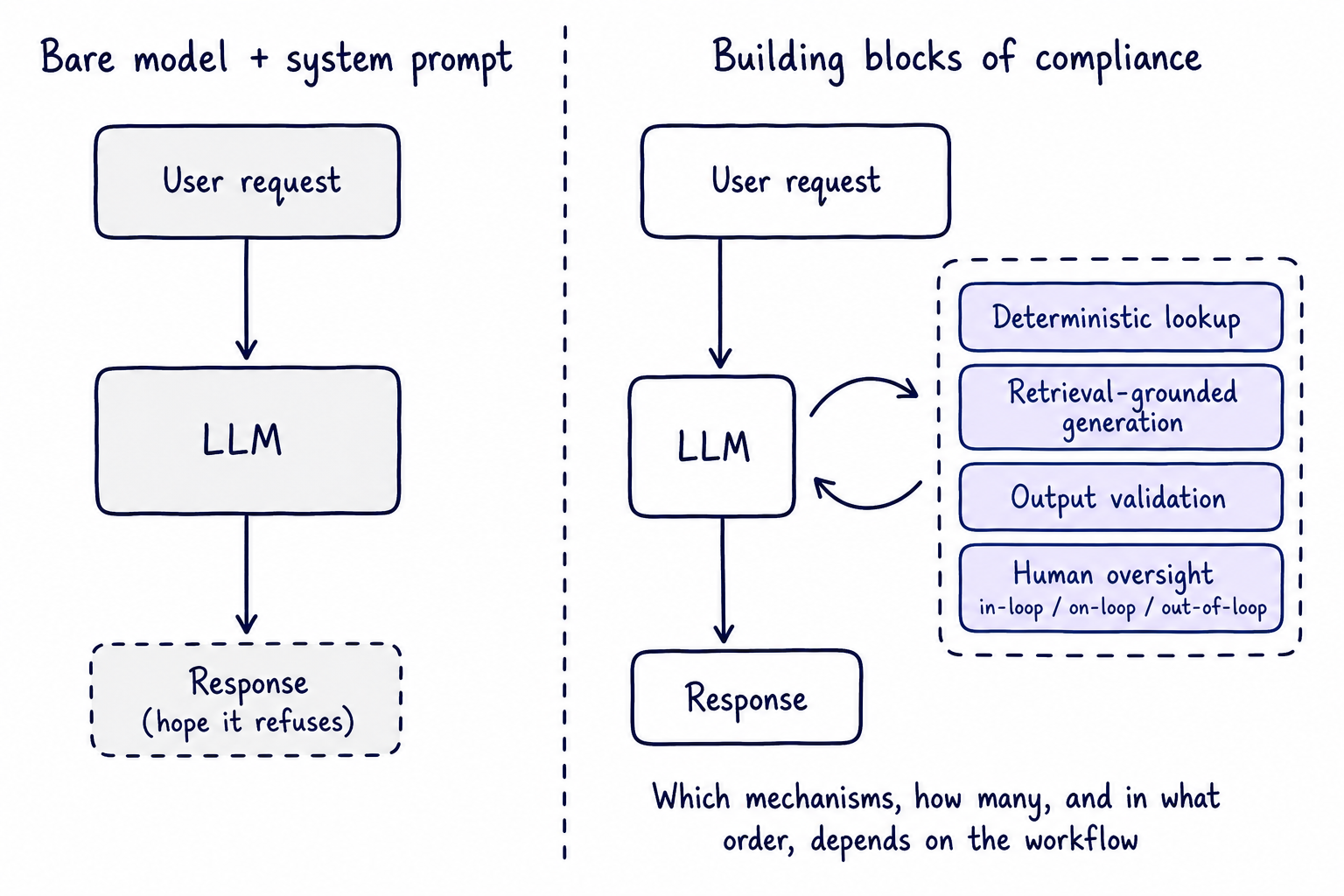
Figure 3: A bare model versus the building blocks of compliance.
A small example from a system I worked on: an AI-assisted workflow producing clinical guidance for a clinical end user. One part of that output, a specific drug dosage, came from a deterministic lookup rather than the model, because you cannot rely on an LLM to get a dosage right every single time, and in that setting every single time is the bar. Other parts of the guidance were grounded in retrieval over our own approved reference material rather than the model's memory. Either way, the boundary was enforced by how the system was built, not by hoping the model would hold its nerve under an awkwardly phrased question.
That is one workflow, built from mechanisms that turn up, in various combinations, across most compliance-sensitive systems:
- Deterministic lookup, for facts that must be exactly right every time: pull the number from a system of record, a rules engine, or an API, rather than generating it.
- Retrieval-grounded generation, for policy or documentation-based answers: ground the response in a governed corpus, cited back to it, rather than the model's memory.
- Output validation against the evidence, checking that what the model produced is actually supported by what was looked up or retrieved, not just that it sounds right.
- Human oversight, sized to the decision: a genuinely high-stakes step gets a human gate the system cannot proceed without, a lower-stakes one gets a human who can step in if something looks wrong, and plenty of decisions warrant no routine human involvement at all. This spectrum has a name in the oversight literature: human-in-the-loop, human-on-the-loop, and human-out-of-the-loop.
These are individually well-established techniques, not one named framework, and none of them is a template on its own. As Figure 3 shows, they are independent mechanisms to draw on rather than one fixed pipeline: most compliance-sensitive systems compose two or three (sometimes the same one more than once at different points in the flow), because what counts as a bad answer differs by domain. A wrong financial recommendation and a wrong clinical dose fail in very different ways, and the mix has to follow the failure.
It should be noted that there are many different tools and frameworks for orchestrating these workflows: personally I use LangGraph quite frequently, because it is flexible and has held up well in production, but it is one option among several.
What carries across every one of these stacks is the same requirement: build compliance into the architecture, rather than relying on the model and prompt, and test the thing you actually run.
How much rigour is enough?
Not every deployment earns the same effort, and pretending otherwise just gets the advice ignored.
| Deployment | Sensible bar |
|---|---|
| Regulated or high-downside | Benchmark seriously against your own policies, design the guardrails into the workflow, and test the whole assembled system |
| Moderate risk | A smaller allowlist and denylist test set before it goes in front of customers |
| Low-stakes internal | A lighter touch, as long as you are honest about what you are not checking |
You do not need a 5,920-query testbed across eight industries to get value from this. You do need something that exercises your own rules, run against the system you are really shipping, not the bare model in isolation. A framework like COMPASS is one way to generate that test set, and it works just as well pointed at a fully architected system as it does at a bare model, which is the whole point: test what you actually run, not what you assume. A modest home-grown set tied to your allowlist and denylist is often enough.
Conclusion
A wall of green benchmark results was never proof that your system would hold up in front of your own customers. That takes rules of your own, a system built to hold them, and evidence that it does. Before you put an LLM in front of customers or staff, two questions are worth being able to answer honestly.
- Can you show test results against your organisation's own rules, not just generic safety scores?
- Did you test the system you are actually shipping, or only the bare model underneath it?
If you are working in this area and want some help in assessing where your own AI systems stand, feel free to get in touch.
References
- Choi, D. et al., COMPASS: A Framework for Evaluating Organization-Specific Policy Alignment in Large Language Models, arXiv:2601.01836, 2026.
- AIM Intelligence, COMPASS repository.
- LangChain, Thinking in LangGraph.
- Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, arXiv:2005.11401, 2020.
- Baum, K. and Laux, J., Constitutive vs. Corrective: A Causal Taxonomy of Human Runtime Involvement in AI Systems, arXiv:2603.19213, 2026.