
Real-world impacts, from courtrooms to hospitals
In an age where AI can outperform humans in complex tasks, it's also spinning tales that would make Baron Munchausen blush. Large Language Models (LLMs), the crown jewels of artificial intelligence, are unintentionally becoming the world's most sophisticated liars. From courtrooms to hospitals, these digital savants are confidently sharing fiction that could rewrite case law or misdiagnose patients.
Welcome to the world of LLM hallucinations, where artificial intelligence meets artificial imagination, and the stakes couldn't be higher.
What Are LLM Hallucinations?
LLM hallucinations occur when an AI model generates text that is factually incorrect, nonsensical, or unrelated to the input prompt. These outputs often appear convincing and coherent, making them particularly problematic.
For example, an LLM might confidently state: "Abraham Lincoln invented the telephone in 1876 to communicate with troops during the Civil War."
This statement combines real historical figures and events but presents entirely false information as fact, showing how LLM hallucinations can blend truth and fiction in misleading ways.
It's All a Hallucination
Interestingly, what we call "hallucinations" are actually a fundamental aspect of how LLMs operate. These models don't retrieve stored information; they generate text by predicting the most likely next word based on learned patterns.
In essence, LLMs are always "making stuff up". We just call it a hallucination when the output is noticeably incorrect or inappropriate. This nature makes LLMs incredibly versatile but highlights the need for critical evaluation of their outputs, especially in high-stakes situations.
Types of Hallucinations
Although there is no universal agreement on the categorisation of hallucinations, a comprehensive study (A Survey on Hallucination in Large Language Models) has identified two main categories:
Factuality Hallucinations
These occur when the LLM produces information that doesn't match reality. There are two types:
Factual Inconsistency: The LLM says something that can be checked but is wrong. Example: "The Eiffel Tower is located in Rome, Italy."
Factual Fabrication: The LLM completely makes something up. Example: "In 2035, scientists discovered a new planet made entirely of cheese."
Faithfulness Hallucinations
These happen when the LLM's response doesn't match what it was asked to do or the context it was given. There are three types:
Instruction Inconsistency: The LLM doesn't follow the specific task it was given. Example: When asked to translate an English question into Spanish, the LLM instead answers the question in English.
Context Inconsistency: The LLM ignores or contradicts the context of the conversation. Example: In a discussion about dogs, the LLM suddenly talks about cat breeds for no reason.
Logical Inconsistency: The LLM contradicts itself or uses flawed reasoning. Example: The LLM states "All mammals are warm-blooded" and then claims "Whales are mammals, but they are cold-blooded."
Impact of Hallucinations
Risk Spectrum
The impact of hallucinations varies widely depending on how they are used. In low-risk situations, like casual chat or creative writing, these errors can be minor or even add an interesting twist. However, in high-risk areas such as medical diagnosis or legal interpretation, hallucinations can cause very real and serious harm.
Understanding this risk spectrum is essential for the responsible use of LLMs. The diagram below illustrates the varying risks associated with different use cases along this spectrum.
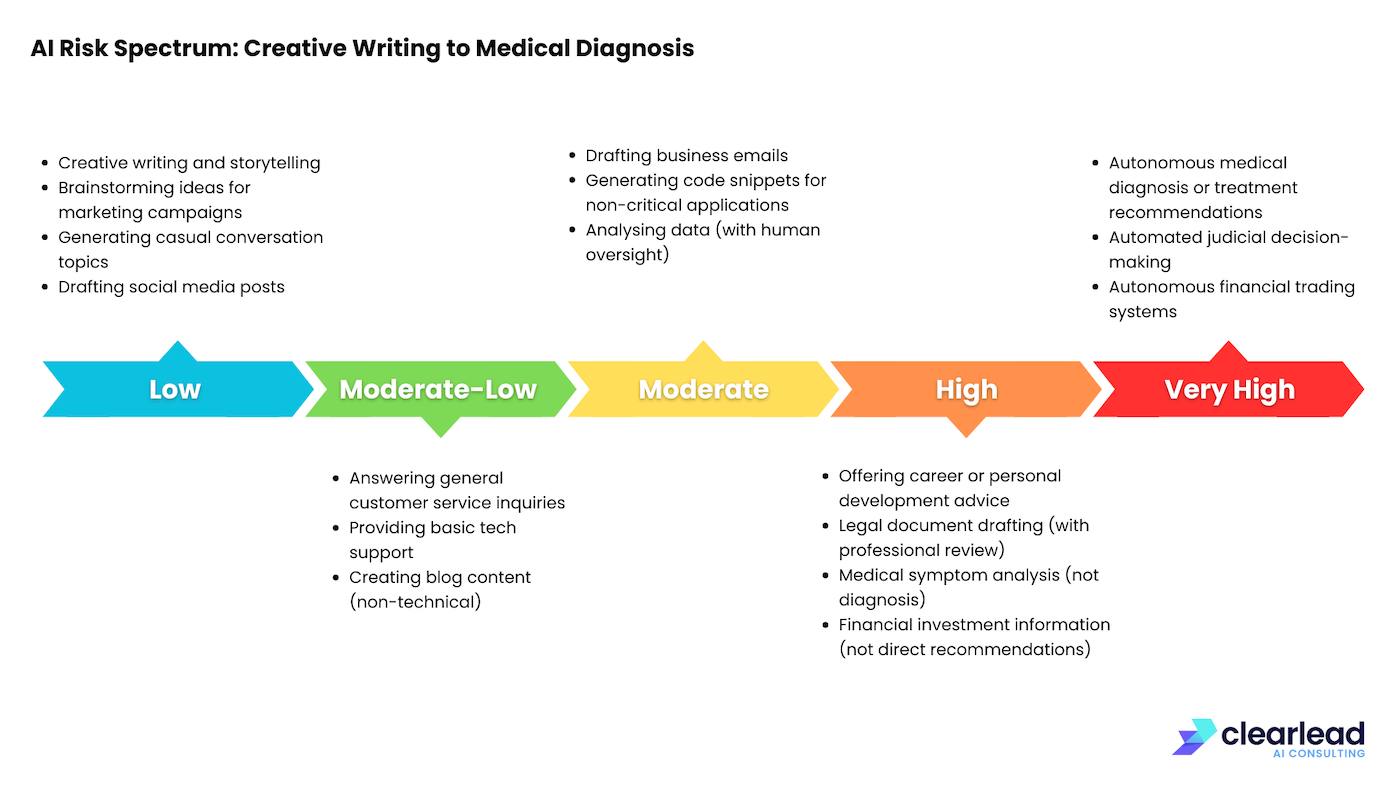
It's important to remember that these risks aren't just for LLMs. Other types of automated systems can also cause problems if people rely on them without proper checks.
For example, in healthcare, mistakes in any automated system for diagnosing illnesses or checking drug interactions can lead to wrong treatments. In legal work, errors in computer systems that review documents or search case law can cause serious problems, even if they don't use LLMs.
The main difference with LLMs is that they can write text that sounds very human-like. This can make their mistakes harder to spot. That's why it's crucial to have humans check the work and to have reliable ways to verify the information.
Legal Risks
A recent study titled Large Legal Fictions by Stanford University researchers revealed concerning rates of hallucinations in legal contexts:
- Popular LLMs like ChatGPT 4 produced inaccurate information at least 58% of the time when asked about legal matters
- Some models showed even higher rates, with inaccuracies occurring up to 88% of the time
- Types of legal hallucinations included factual errors about case details, the creation of non-existent cases, and incorrect attribution of opinions to judges or courts
These findings raise important concerns about the use of LLMs in legal practice: risk of malpractice, decreased trust in AI systems within the legal community, and increased vulnerability of individuals representing themselves in court.
Healthcare Risks
In the healthcare sector, LLM hallucinations can pose significant risks:
- Generation of inaccurate information about drug interactions or dosages
- Misrepresentation of symptoms or diseases
- Incorrect treatment recommendations
- Inaccurate descriptions of medical procedures
The potential for LLMs to misinterpret or fabricate clinical data could lead to incorrect diagnoses or treatment plans, emphasising the importance of human oversight and verification in clinical applications of AI.
Causes and Mitigation Strategies for Hallucinations
Training Data Issues: Biases, inaccuracies, or gaps in the training dataset can lead to hallucinations. Mitigation: Improve training data quality by ensuring diverse, balanced, and well-curated datasets.
Model Architecture Limitations: Flaws in the underlying neural network structure can contribute to hallucinations. Mitigation: Develop more robust neural network designs.
Inference Strategy Problems: Issues with the way the LLM puts words together can result in hallucinations. Mitigation: Improve the methods used for constructing responses to make them more accurate and relevant.
Prompt Engineering Challenges: Ambiguous or imprecise input prompts can lead to hallucinations. Mitigation: Craft clear, specific prompts to guide the LLM effectively.
Optimisation Issues: Over-emphasis on certain metrics during model training can result in hallucinations. Mitigation: Balance performance goals by considering multiple metrics, including those that measure hallucination tendencies.
Lack of External Knowledge Integration: Relying solely on learned information without access to current data can lead to hallucinations. Mitigation: Implement fact-checking by integrating external knowledge sources.
Single Model Limitations: Using a single model can amplify its weaknesses and biases. Mitigation: Use multiple models together for increased reliability.
Lack of Human Oversight: Fully automated systems without human checks can spread hallucinations. Mitigation: Include human experts in reviewing critical LLM outputs.
Difficulty in Detecting Hallucinations: The convincing nature of hallucinations makes them hard to spot automatically. Mitigation: Develop methods to check LLM outputs for consistency and accuracy.
Lack of Ongoing Evaluation: LLMs can develop new tendencies to hallucinate over time. Mitigation: Regularly test and evaluate LLMs to track and improve their performance.
Best Practices for Working with LLMs
In conjunction with the mitigation strategies already mentioned, when working with LLMs it's important to also consider the following best practices:
- Set Clear Expectations: Educate users about LLM limitations and the potential for inaccuracies
- Implement Robust Safeguards: Design systems with checks to flag potential errors, such as using multiple models for cross-verification
- Maintain Human Oversight: Ensure humans remain in the loop for critical decisions, encouraging verification and questioning of LLM outputs
- Regularly Update and Evaluate: Continuously monitor performance, retrain as needed, and use benchmarks to track improvements
- Stay Informed: Keep up with the latest research and advancements in hallucination mitigation techniques
Conclusion
Large Language Models have attracted significant interest, particularly in the business world, where they're seen as excellent tools for increasing efficiency across various sectors. However, as this article has shown, these AI models can often present information with more confidence than they should.
Given the risks associated with hallucinations, careful checking is crucial, especially in high-stakes environments such as healthcare, legal contexts, or critical decision-making processes.
Organisations planning to use LLMs should approach their implementation with a balanced view. While embracing the efficiency these models offer, it's essential to establish strong verification processes and maintain human oversight.
Whether you're implementing LLMs in your organisation or simply curious about their impact, continuing to learn and discuss these challenges is key to harnessing the potential of AI responsibly. If you're seeking strategic guidance or technical solutions to address LLM hallucinations in your business, we're here to help.
References
-
Doshi-Velez, F. and Kim, B. (2017). Towards A Rigorous Science of Interpretable Machine Learning. arXiv:1702.08608.
-
Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions. Nature Machine Intelligence, 1(5), 206–215.
-
Vaswani et al. (2017). Attention is All you Need. Advances in Neural Information Processing Systems, 5998–6008.
-
Selvaraju et al. (2017). Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. ICCV, 618–626.
-
Ribeiro, M. T., Singh, S., and Guestrin, C. (2016). Why Should I Trust You?: Explaining the Predictions of Any Classifier. KDD, 1135–1144.
-
Lundberg, S. M. and Lee, S. I. (2017). A Unified Approach to Interpreting Model Predictions. NeurIPS, 4765–4774.
-
Brown et al. (2020). Language Models are Few-Shot Learners. NeurIPS, 1877–1901.
-
Zhang et al. (2024). The limits of fair medical imaging AI in real-world generalization. Nature Medicine, 30(2), 389–399.
-
Misheva, B. H. (2021). Explainable AI in Credit Risk Management. arXiv:2103.00949.
-
Carvalho, D. V., Pereira, E. M., and Cardoso, J. S. (2019). Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics, 8(8), 832.