New Benchmark Data Shows Rapid Progress on Complex Professional Tasks
OpenAI's GDPval benchmark shows that top AI models now match expert-level quality on nearly half of complex professional tasks.
Critically, these aren't simple routine tasks: they're substantial work from professionals with an average of 14 years of experience, with the tasks themselves taking experts 7 hours to complete.
The key findings:
- When tasks have clear specifications and defined success criteria, AI can reliably handle expert-level work
- Performance has tripled in just 12 months
- This gives us a clear benchmark of what's possible with AI on high-end workplace tasks
What Makes GDPval Different: Competing Against Real Experts
Most AI benchmarks test models on structured puzzles or academic problems, but GDPval is quite different:
- It defines tasks based on actual work from industry professionals with an average of 14 years' experience, not interns or junior staff
- The study covers nine major economic sectors (chosen based on those contributing over 5% to US GDP)

Sectors covered by GDPval — Source: OpenAI
The 44 occupations include software developers, lawyers, nurses, financial advisers, real estate agents, social workers, industrial engineers, pharmacists, and customer service representatives.
The tasks themselves are far from simple, with the average task taking human experts 7 hours to complete. These cover complex deliverables like financial reports, medical assessments, sales brochures, and legal documents.
The evaluation process also involves expert (human) graders, who evaluate the outputs using blind comparisons. They didn't know which was AI and which was human, which removes any bias from the evaluation.
It should be clear that this is an extremely high bar. AI isn't competing with new hires doing basic tasks; it's competing with experienced professionals doing genuinely complex work.
The Top Performer: Claude Opus 4.1
Overall, Anthropic's Claude Opus 4.1 model outperformed all models, including OpenAI's own GPT-5.
This is particularly significant given that OpenAI conducted the study. The fact that their own models didn't come out on top actually lends credibility to the research, and since this model has scored highly across a range of other benchmarking tasks it is not a surprise.
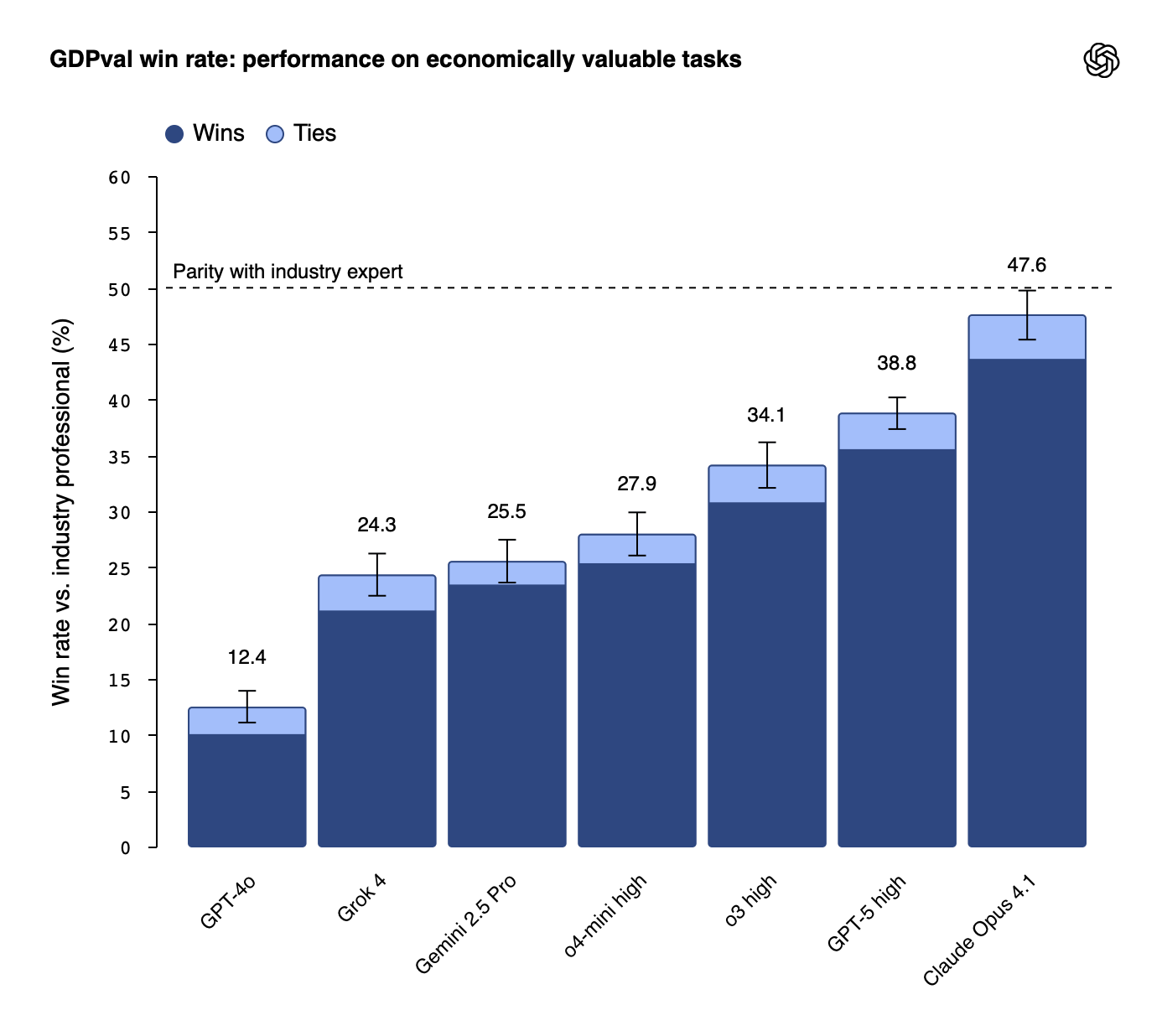
Model performance based on human pairwise comparisons — Source: OpenAI
That being said, different models demonstrated strengths in different areas. For example, Claude excelled in aesthetics and formatting, particularly when working with formats such as PDF and PowerPoint, while other models took the lead in some other distinct tasks. So although Claude was a clear leader overall, there is no single "best" model for all types of work.
Understanding What 47.6% Actually Means
In blind comparisons, expert graders rated Claude's deliverables as equal to or better than work from industry experts on 47.6% of tasks.
In the paper, the authors describe this as "approaching parity" with an expert. True parity would be 50/50, where a human reviewer genuinely can't tell the difference between AI and the human expert's work.
At 47.6%, we're extremely close to this threshold.
The Rapid Improvement Trajectory
The performance improvement over a single year is striking:
- GPT-4o (early 2024): 13.7% expert-level performance
- GPT-5 (latest): 40%+ expert-level performance
- Claude Opus 4.1: 47.6% expert-level performance
That's nearly 3.5× improvement in roughly 12 months.
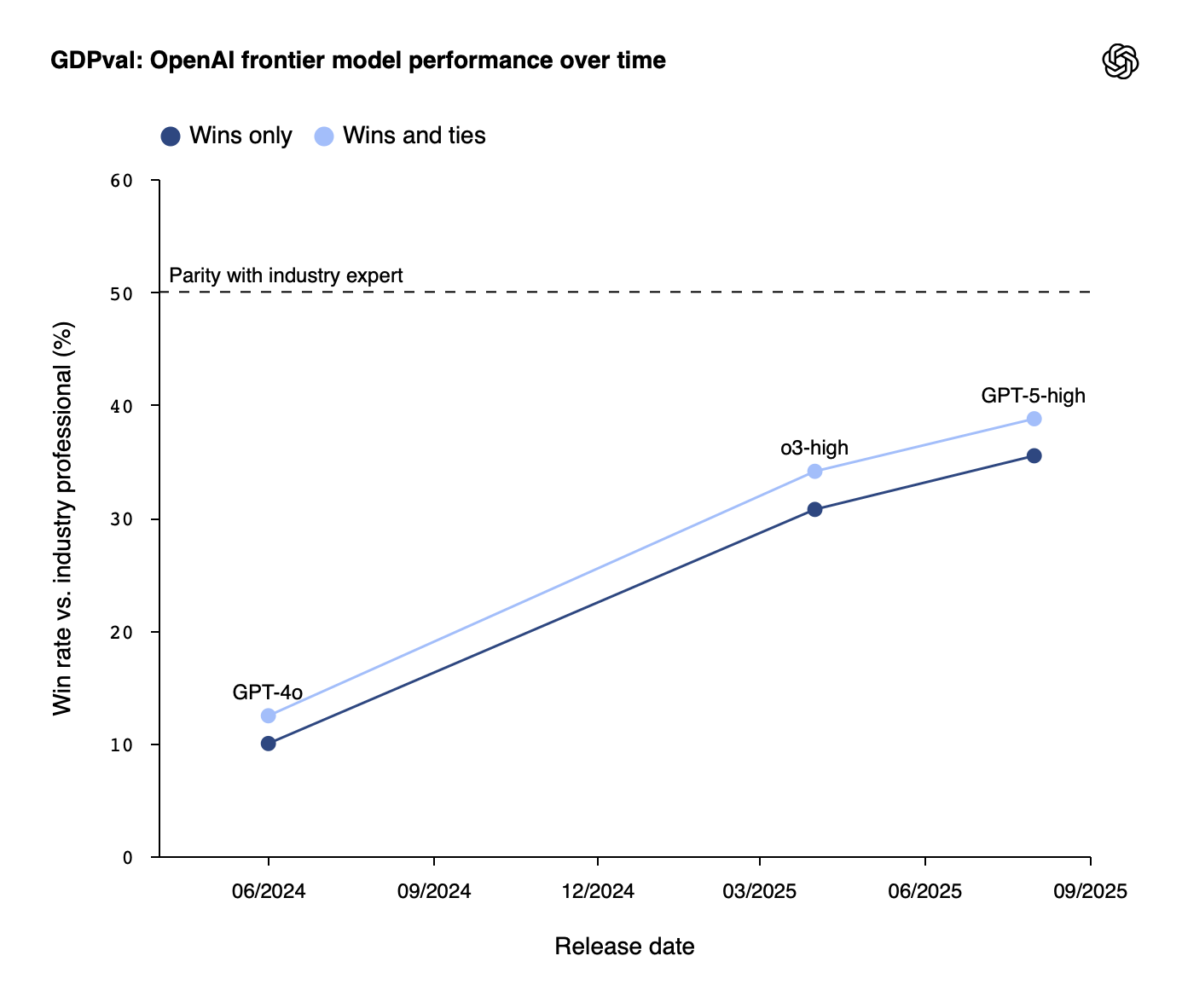
Performance on GDPval tasks more than tripled in a year — Source: OpenAI
The study found that "frontier" model performance is improving roughly linearly over time. Obviously we can't assume that this linear trend will continue indefinitely, but if it does, then "true parity" could be reached very soon.
When AI Works and When It Doesn't
As mentioned earlier, there are certain tasks where models perform well and others where different models tend to perform better. There are also certain tasks where we see common patterns of success and failure.
Some occupations saw AI match expert performance 8 out of 10 times, while others fell well below 40%.
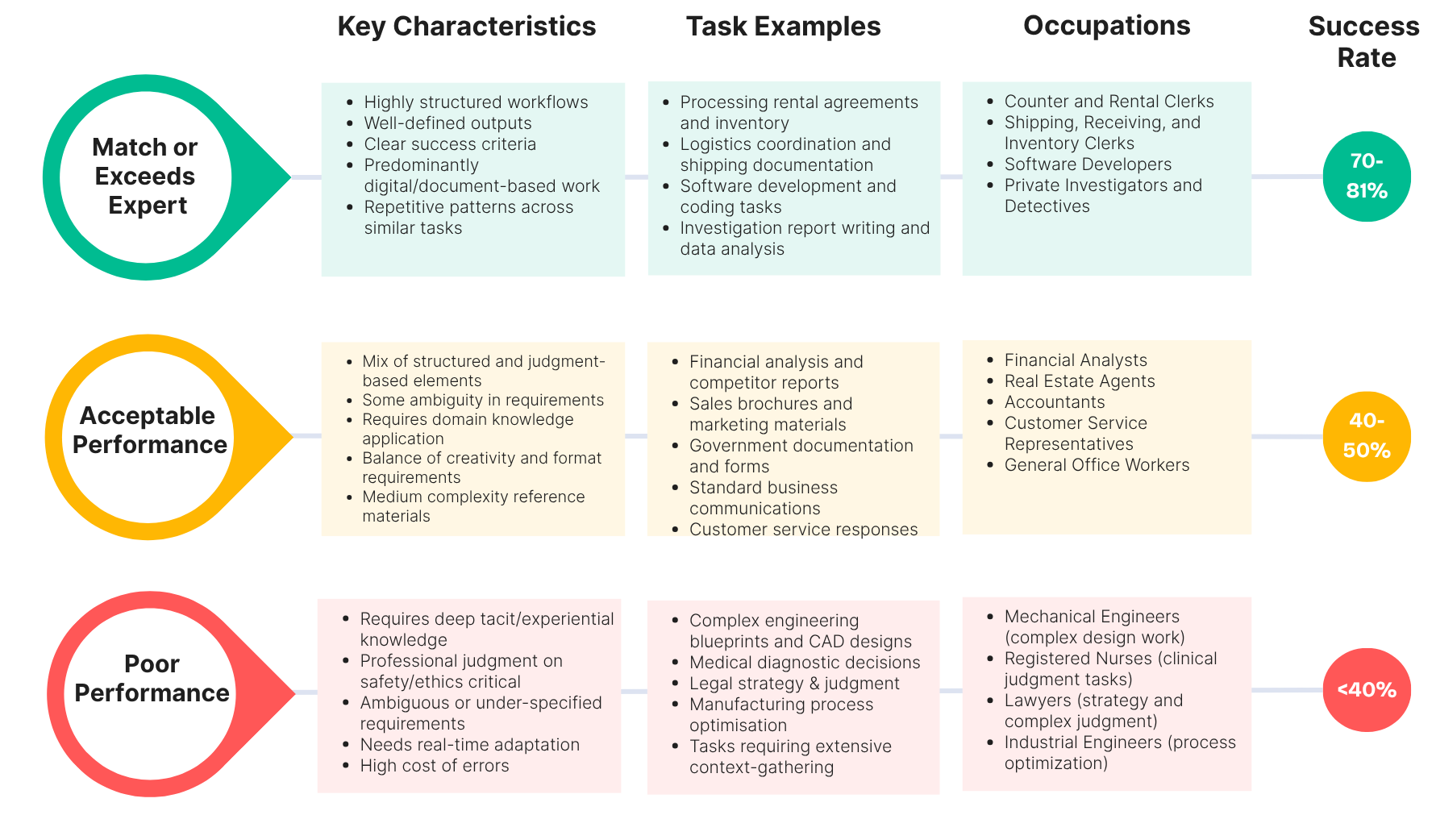
For the key insights here we have to look at the task characteristics, not the sector or job title.
Tasks where the AI models excel share common traits:
- Structured workflows
- Well-defined outputs
- Clear success criteria
Tasks where it struggles require:
- Experience-based knowledge
- Safety or ethics-based judgements
- Navigating ambiguous requirements
Common Failures
When AI fails, it's usually for predictable reasons:
Instruction following (most common): Missing requirements buried in prompts, ignoring constraints, using wrong formats despite clear instructions.
Formatting issues: GPT-5 showed formatting errors in 86% of PowerPoint files. Black square artefacts appeared in over half of PDFs (though fixable with better prompts).
Accuracy problems: Hallucinating data, calculation errors, misinterpreting reference materials, where the AI presents wrong information with complete confidence.
Context and ambiguity: When prompts were deliberately less specific, performance dropped significantly. AI models typically struggle to determine what's relevant or figure out "what to work on" when context is ambiguous.
About 29% of failures were serious, where work was not fit for professional use. While 3% were found with critical errors that could cause real harm: wrong medical diagnoses, dangerous recommendations, relationship-damaging content. This is why expert oversight is critical for certain types of tasks.
The practical takeaway: if you can write down clear specifications and define success objectively, AI will likely perform well. If success requires expertise that's hard to articulate, it won't.
What This Means for Your Organisation
Context Matters: These Were Expert-Level Tasks
It's important to reiterate that GDPval tested AI against professionals with an average of 14 years' experience on complex, multi-hour tasks. This sets a very high bar.
In practice, many business tasks aren't expert-level work:
- Routine documentation
- Standard reports
- Data entry
- Basic analysis
These often fall into the top tier (70–81% success rates) when properly defined. If AI can match experts on complex tasks nearly half the time, it can handle simpler, well-specified work even more reliably.
Is This Task AI-Ready?
The pattern is clear: structured tasks with written specifications succeed. Ambiguous tasks requiring nuanced professional knowledge tend to fail.
Good candidates: Clear specifications, checkable output, repetitive patterns.
Poor candidates: Safety/ethics judgement, tacit knowledge, ambiguous requirements, catastrophic error risk.
The test: Could someone with no domain expertise complete this task from a written brief? If not, AI will probably struggle.
Beyond Off-the-Shelf Models
It's important to note that although the GDPval tasks go beyond simple text prompts (coming with reference files and context), they are still evaluating the same base model (e.g. Claude Opus 4.1). What I am getting at is that the underlying model itself has not been fine-tuned or optimised for the individual tasks.
This in itself makes the performance figures even more impressive, since we know that superior performance could be achieved by developing specific models or fine-tuning existing models.
For more complex or specialised tasks, customised solutions — fine-tuned models, specialised prompts, or task-specific workflows — can achieve higher success rates than these benchmarks suggest.
Another important aspect to remember is that in reality, it doesn't have to be a binary case of tasks being completed solely by AI or humans. For many complex tasks, using AI systems in a collaborative manner can offer huge benefits.
Looking Forward
These latest benchmark figures give us a real indication of how well we can expect AI systems to perform on complex tasks, and also give us an insight into the cases where they excel as well as perform poorly.
Based on this evidence, we can already see that for a range of tasks, these systems are already matching or exceeding human performance.
For any organisations looking to integrate AI models, it should be clear that these systems offer tremendous value, particularly when applied in the appropriate manner.
Ready to Explore AI Integration for Your Organisation?
If you're interested in understanding how AI can handle specific tasks in your business or want guidance on identifying which areas might benefit from AI integration, I'd be happy to discuss it.
I work with organisations to assess their workflows, identify suitable applications for AI, and implement solutions that deliver practical results. Whether you're looking for strategic advice or hands-on implementation, get in touch.